
Ali Ramezani-Kebrya
I am an Associate Professor (with tenure) in the Department of Informatics at the University of Oslo (UiO), a Research Theme Leader at the Norwegian Center for Knowledge-driven Machine Learning (Integreat), a Principal Investigator at TRUST – The Norwegian Centre for Trustworthy AI, a Senior Researcher at MishMash Centre for AI and Creativity, and a member of the European Laboratory for Learning and Intelligent Systems (ELLIS) Society. I serve as an Area Chair of NeurIPS, ICLR, ICML, and AISTATS and Action Editor for Transactions on Machine Learning Research. I have received FRIPRO Grant for Early Career Scientists and Top 10% Area Chair Recognition at NeurIPS 2025.
Before joining UiO, I was a Senior Scientific Collaborator at EPFL, working with Prof. Volkan Cevher in Laboratory for Information and Inference Systems (LIONS). Before joining LIONS, I was an NSERC Postdoctoral Fellow at the Vector Institute in Toronto working with Prof. Daniel M. Roy. I received my Ph.D. from the University of Toronto where I was very fortunate to be advised by Prof. Ben Liang and Prof. Min Dong.
My current research is focused on understanding how the input data distribution is encoded within layers of neural networks and developing theoretical concepts and practical tools to minimize the statistical risk under resource constraints and realistic settings referring to statistical and system characteristics contrary to an ideal learning setting. My current research topics: Trustworthy AI, Deep Learning, Learning Theory, LLMs and Reasoning Models, and Emotion Recognition and Co-creative AI.
Recent News
- 2/2026 Two exciting PhD positions are available: Deadline March 1st and Deadline March 8th.
- 1/2026 One Submission and One Accept at ICLR 2026!
- 1/2026 Christina Runkel has joined us at INTEGREAT and UiO. Welcome Christina!
- 12/2025 I serve as an Area Chair of ICLR 2026.
- 11/2025 Ali Ramezani-Kebrya has received Top 10% Area Chair Recognition at NeurIPS 2025!
- 11/2025 TRUST – The Norwegian Centre for Trustworthy AI has launched today with a keynote by Yoshua Bengio, Sigrun Aasland, and Karianne Tung!
- 11/2025 Our paper Aligning Attention with Human Rationales for Self-Explaining Hate Speech Detection has been accepted to AAAI 2026!
- 11/2025 Tobias Müller has started his PhD at UiO. Welcome Tobias!
- 10/2025 Ali Ramezani-Kebrya will be a Principal Investigator at TRUST – The Norwegian Centre for Trustworthy AI!
- 8/2025 Adrian Duric has started his PhD at UiO. Welcome Adrian!
- 5/2025 Our paper Quantized Optimistic Dual Averaging with Adaptive Layer-wise Compression has been accepted to ICML 2025.
- 4/2025 I have received a FRIPRO Grant for Early Career Scientists for project Machine Learning in Real World (MLReal).
1/2025 Our paper Addressing Label Shift in Distributed Learning via Entropy Regularization has been accepted to ICLR 2025.
- 11/2024 I will serve as an Action Editor for Transactions on Machine Learning Research.
- 10/2024 I will serve as an Area Chair of AISTATS 2025.
- 8/2024 Integreat is officially launched.
- 4/2024 I have PhD Position in ML.
- 3/2024 I will serve as an Area Chair of NeurIPS 2024.
- 2/2024 We have one postdoc position in “Joint Physics-informed and Data-driven Complex Dynamical System Solvers”.
- 2/2024 Our paper Mixed Nash for Robust Federated Learning has been accepted to the Transactions on Machine Learning Research.
- 2/2024 The Research Excellence Center SFI Visual Intelligence has recognized our work Federated Learning under Covariate Shifts with Generalization Guarantees as Spotlight Publications from 2023!
- 1/2024 Our paper On the Generalization of Stochastic Gradient Descent with Momentum has been accepted to the Journal of Machine Learning Research.
Selected Publications
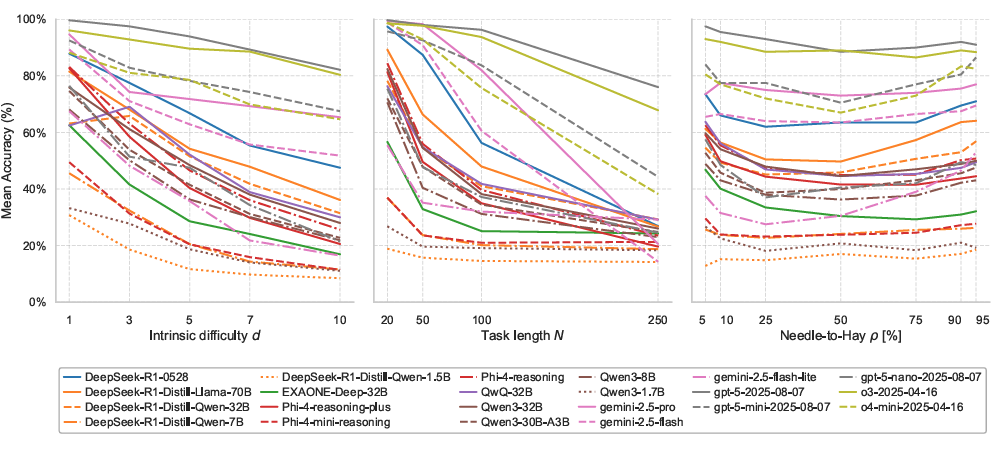 Inspired by Cognitive Load Theory, we developed logic puzzles with controlling proxies of three types of cognitive load on human working memory when solving problems. CogniLoad generates random logic puzzles very efficiently without requiring any external knowledge or retrieval just assessing inherent brain of reasoning LLMs. 22 SotA reasoning LLMs are evaluated.
Inspired by Cognitive Load Theory, we developed logic puzzles with controlling proxies of three types of cognitive load on human working memory when solving problems. CogniLoad generates random logic puzzles very efficiently without requiring any external knowledge or retrieval just assessing inherent brain of reasoning LLMs. 22 SotA reasoning LLMs are evaluated.
Daniel Kaiser, Arnoldo Frigessi, Ali Ramezani-Kebrya, and Benjamin Ricaud, CogniLoad: A Synthetic Natural Language Reasoning Benchmark With Tunable Length, Intrinsic Difficulty, and Distractor Density, ICLR 2026.
pdf arXiv openreview
 As algorithms make more decisions that affect people’s lives. It is crucial that we understand their reasoning. We introduce Supervised Rational Attention (SRA) that aligns transformer attention with human rationales to achieve better explainability and improved fairness in hate speech detection while maintaining competitive accuracy. SRA achieves 2.4× better explainability vs. the strongest baseline.
As algorithms make more decisions that affect people’s lives. It is crucial that we understand their reasoning. We introduce Supervised Rational Attention (SRA) that aligns transformer attention with human rationales to achieve better explainability and improved fairness in hate speech detection while maintaining competitive accuracy. SRA achieves 2.4× better explainability vs. the strongest baseline.
Brage Eilertsen, Røskva Bjørgfinsdóttir, Francielle Vargas, and Ali Ramezani-Kebrya, Aligning Attention with Human Rationales for Self-Explaining Hate Speech Detection, AAAI 2026.
pdf demo arXiv poster
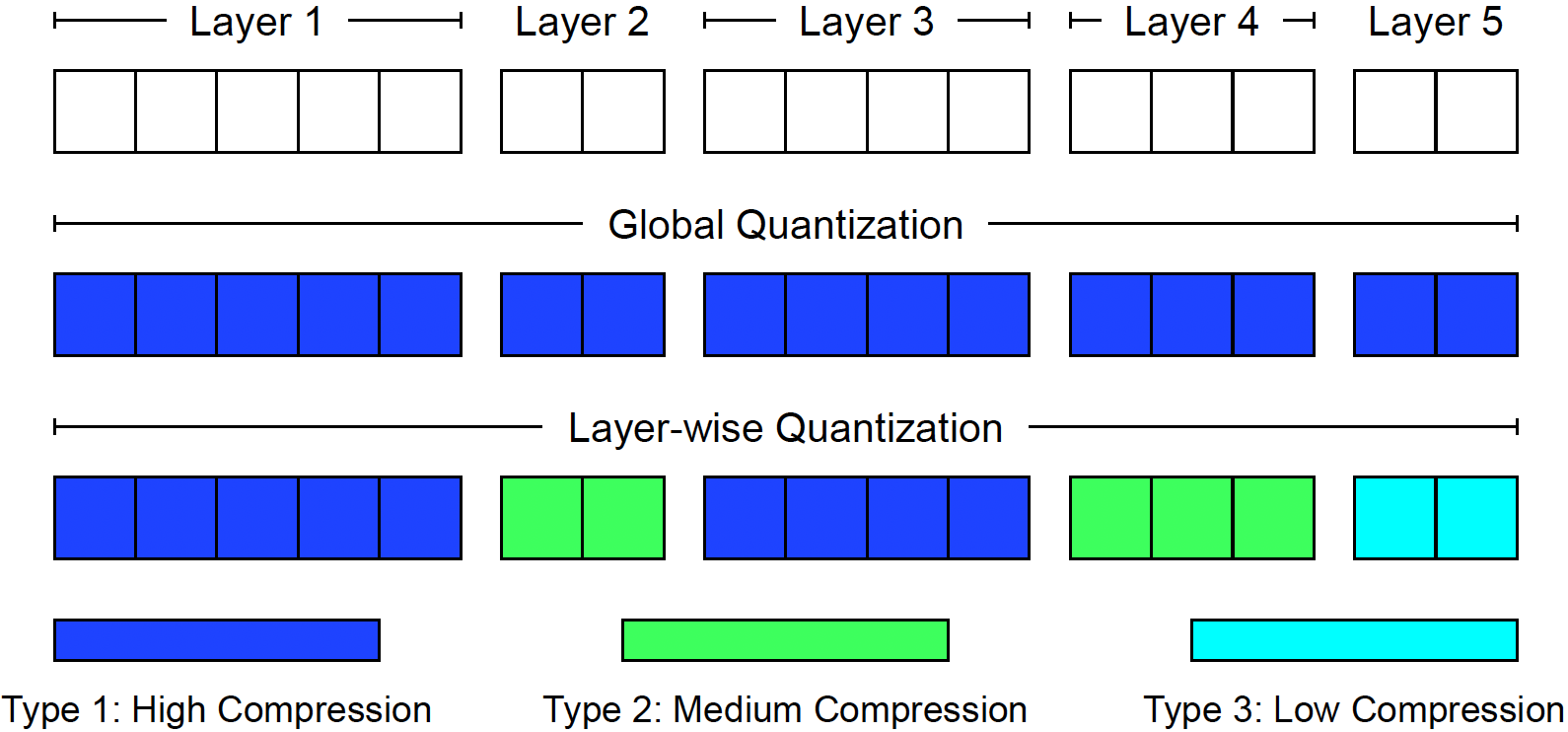 We have developed a general layer-wise quantization framework taking into account the statistical heterogeneity across layers and an efficient solver for distributed variational inequalities. We establish tight variance and code-length bounds for layer-wise quantization, which generalize the bounds for global quantization frameworks. We empirically achieve up to a 150% speedup over the baselines in end-to-end training time for training Wasserstein GAN on 12+ GPUs.
We have developed a general layer-wise quantization framework taking into account the statistical heterogeneity across layers and an efficient solver for distributed variational inequalities. We establish tight variance and code-length bounds for layer-wise quantization, which generalize the bounds for global quantization frameworks. We empirically achieve up to a 150% speedup over the baselines in end-to-end training time for training Wasserstein GAN on 12+ GPUs.
Anh Duc Nguyen, Ilia Markov, Frank Zhengqing Wu, Ali Ramezani-Kebrya, Kimon Antonakopoulos, Dan Alistarh, and Volkan Cevher, Layer-wise Quantization for Quantized Optimistic Dual Averaging, ICML 2025. pdf poster openreview arXiv
{kind=link}
 We have introduced a method to minimize overall true risk in distributed settings under inter-node and intra-node label shifts. We improve test-to-train density ratio estimation through Shannon entropy-based regularization. Our method encourages smoother and more reliable predictions that account for inherent uncertainty in the data with a better approximation of class conditional probabilities, and achieves up to 20% improvement in average test error in imbalanced settings approaching an upper bound.
We have introduced a method to minimize overall true risk in distributed settings under inter-node and intra-node label shifts. We improve test-to-train density ratio estimation through Shannon entropy-based regularization. Our method encourages smoother and more reliable predictions that account for inherent uncertainty in the data with a better approximation of class conditional probabilities, and achieves up to 20% improvement in average test error in imbalanced settings approaching an upper bound.
Zhiyuan Wu*, Changkyu Choi*, Xiangcheng Cao, Volkan Cevher, and Ali Ramezani-Kebrya, Addressing Label Shift in Distributed Learning via Entropy Regularization, ICLR 2025.
pdf code openreview arXiv
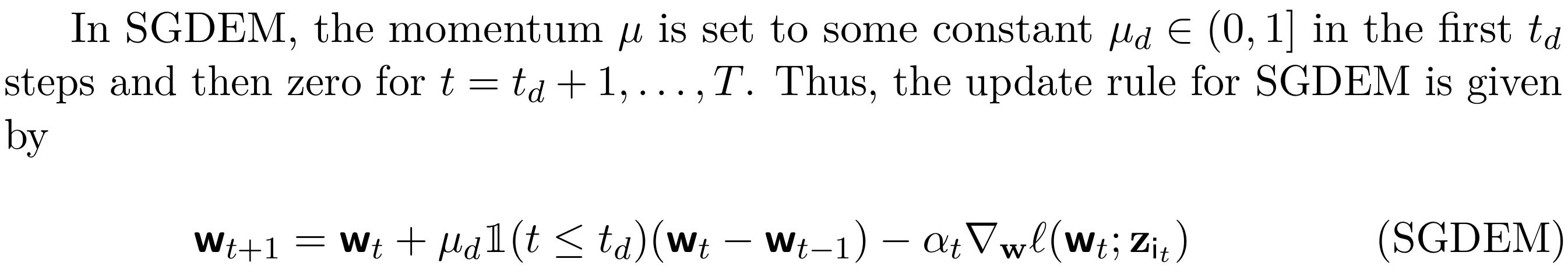 We have shown it is crucial to establish an appropriate balance between the optimization error associated with the empirical risk and the generalization error when accelerating SGD with momentum and established generalization error bounds and explicit convergence rates for SGD with momentum under a broad range of hyperparameters including a general step-size rule. For smooth Lipschitz loss functions, we analyze SGD with early momentum (SGDEM) under a broad range of step-sizes, and show that it can train machine learning models for multiple epochs with a guarantee for generalization.
We have shown it is crucial to establish an appropriate balance between the optimization error associated with the empirical risk and the generalization error when accelerating SGD with momentum and established generalization error bounds and explicit convergence rates for SGD with momentum under a broad range of hyperparameters including a general step-size rule. For smooth Lipschitz loss functions, we analyze SGD with early momentum (SGDEM) under a broad range of step-sizes, and show that it can train machine learning models for multiple epochs with a guarantee for generalization.
Ali Ramezani-Kebrya, Kimon Antonakopoulos, Volkan Cevher, Ashish Khisti, and Ben Liang, On the Generalization of Stochastic Gradient Descent with Momentum, Journal of Machine Learning Research, vol. 25, pp. 1-56, Jan. 2024.
pdf bib arXiv
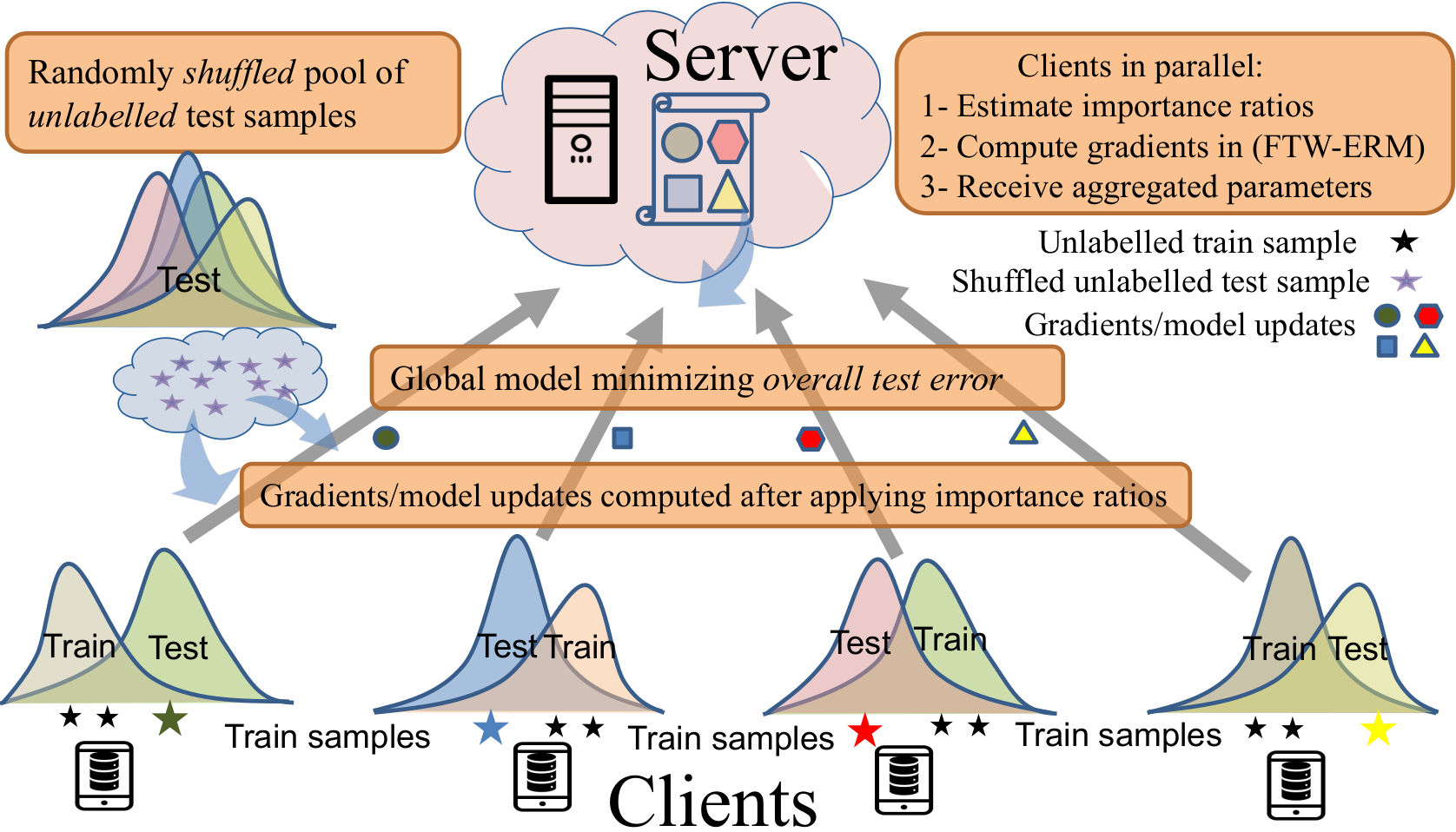 Even for a single client, the distribution shift between training and test data, i.e., intra-client distribution shift,has been a major challenge for decades. For instance, scarce disease data for training and test in a local hospital can be different. We focus on the overall generalization performance on multiple clients and modify the classical ERM to obtain an unbiased estimate of an overall true risk minimizer under intra-client and inter-client covariate shifts, develop an efficient density ratio estimation method under stringent privacy requirements of federated learning, and show importance-weighted ERM achieves smaller generalization error than classical ERM.
Even for a single client, the distribution shift between training and test data, i.e., intra-client distribution shift,has been a major challenge for decades. For instance, scarce disease data for training and test in a local hospital can be different. We focus on the overall generalization performance on multiple clients and modify the classical ERM to obtain an unbiased estimate of an overall true risk minimizer under intra-client and inter-client covariate shifts, develop an efficient density ratio estimation method under stringent privacy requirements of federated learning, and show importance-weighted ERM achieves smaller generalization error than classical ERM.
Ali Ramezani-Kebrya*, Fanghui Liu*, Thomas Pethick*, Grigorios Chrysos, and Volkan Cevher, Federated Learning under Covariate Shifts with Generalization Guarantees, Transactions on Machine Learning Research, June 2023.
pdf code openreview
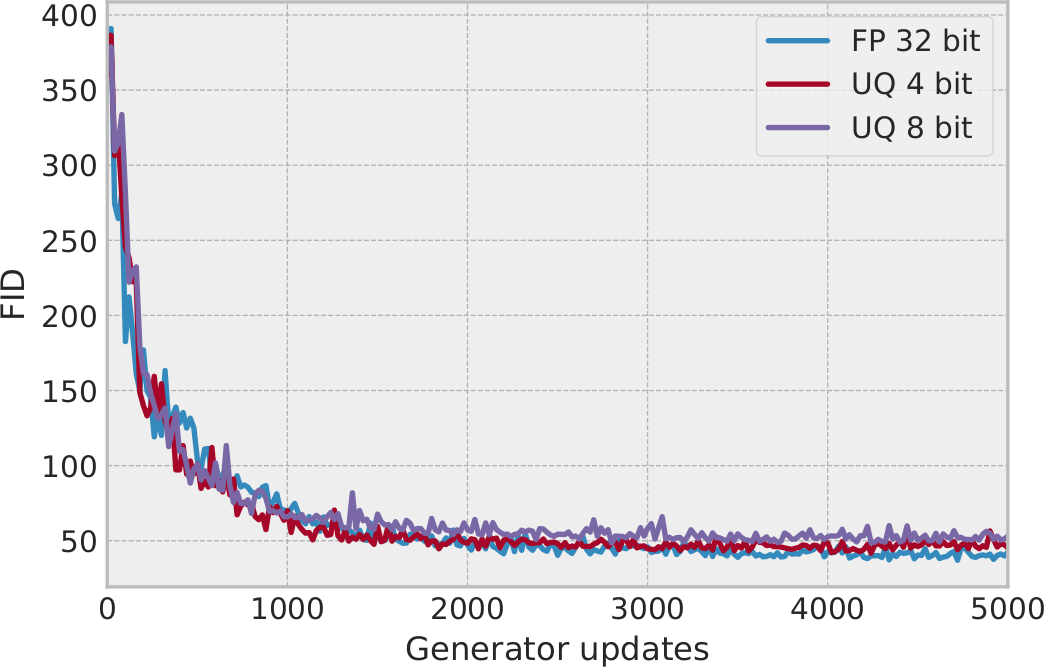 Beyond supervised learning, we accelerate large-scale monotone variational inequality problems with applications such as training GANs in distributed settings. We propose quantized generalized extra-gradient (Q-GenX) family of algorithms with the optimal rate of convergence and achieve noticeable speedups when training GANs on multiple GPUs without performance degradation.
Beyond supervised learning, we accelerate large-scale monotone variational inequality problems with applications such as training GANs in distributed settings. We propose quantized generalized extra-gradient (Q-GenX) family of algorithms with the optimal rate of convergence and achieve noticeable speedups when training GANs on multiple GPUs without performance degradation.
Ali Ramezani-Kebrya*, Kimon Antonakopoulos*, Igor Krawczuk*, Justin Deschenaux*, and Volkan Cevher, Distributed Extra-gradient with Optimal Complexity and Communication Guarantees, ICLR 2023.
pdf bib code openreview
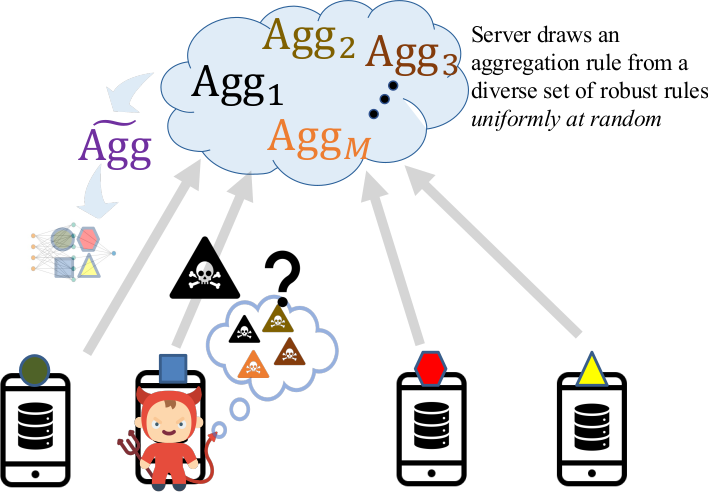 ML models are vulnerable to various attacks at training and test time including data/model poisoning and adversarial examples. We introduce MixTailor, a scheme based on randomization of the aggregation strategies that makes it impossible for the attacker to be fully informed. MixTailor: Mixed Gradient Aggregation for Robust Learning Against Tailored Attacks increases computational complexity of designing tailored attacks for an informed adversary.
ML models are vulnerable to various attacks at training and test time including data/model poisoning and adversarial examples. We introduce MixTailor, a scheme based on randomization of the aggregation strategies that makes it impossible for the attacker to be fully informed. MixTailor: Mixed Gradient Aggregation for Robust Learning Against Tailored Attacks increases computational complexity of designing tailored attacks for an informed adversary.
Ali Ramezani-Kebrya*, Iman Tabrizian*, Fartash Faghri, and Petar Popovski, MixTailor: Mixed Gradient Aggregation for Robust Learning Against Tailored Attacks, Transactions on Machine Learning Research, Oct. 2022.
pdf bib code arXiv openreview
 Overparameterization refers to the important phenomenon where the width of a neural network is chosen such that learning algorithms can provably attain zero loss in nonconvex training. In Subquadratic Overparameterization for Shallow Neural Networks, we achieve the best known bounds on the number of parameters that is sufficient for gradient descent to converge to a global minimum with linear rate and probability approaching to one.
Overparameterization refers to the important phenomenon where the width of a neural network is chosen such that learning algorithms can provably attain zero loss in nonconvex training. In Subquadratic Overparameterization for Shallow Neural Networks, we achieve the best known bounds on the number of parameters that is sufficient for gradient descent to converge to a global minimum with linear rate and probability approaching to one.
Chaehwan Song*, Ali Ramezani-Kebrya*, Thomas Pethick, Armin Eftekhari, and Volkan Cevher, Subquadratic Overparameterization for Shallow Neural Networks, NeurIPS 2021.
pdf bib code arXiv openreview
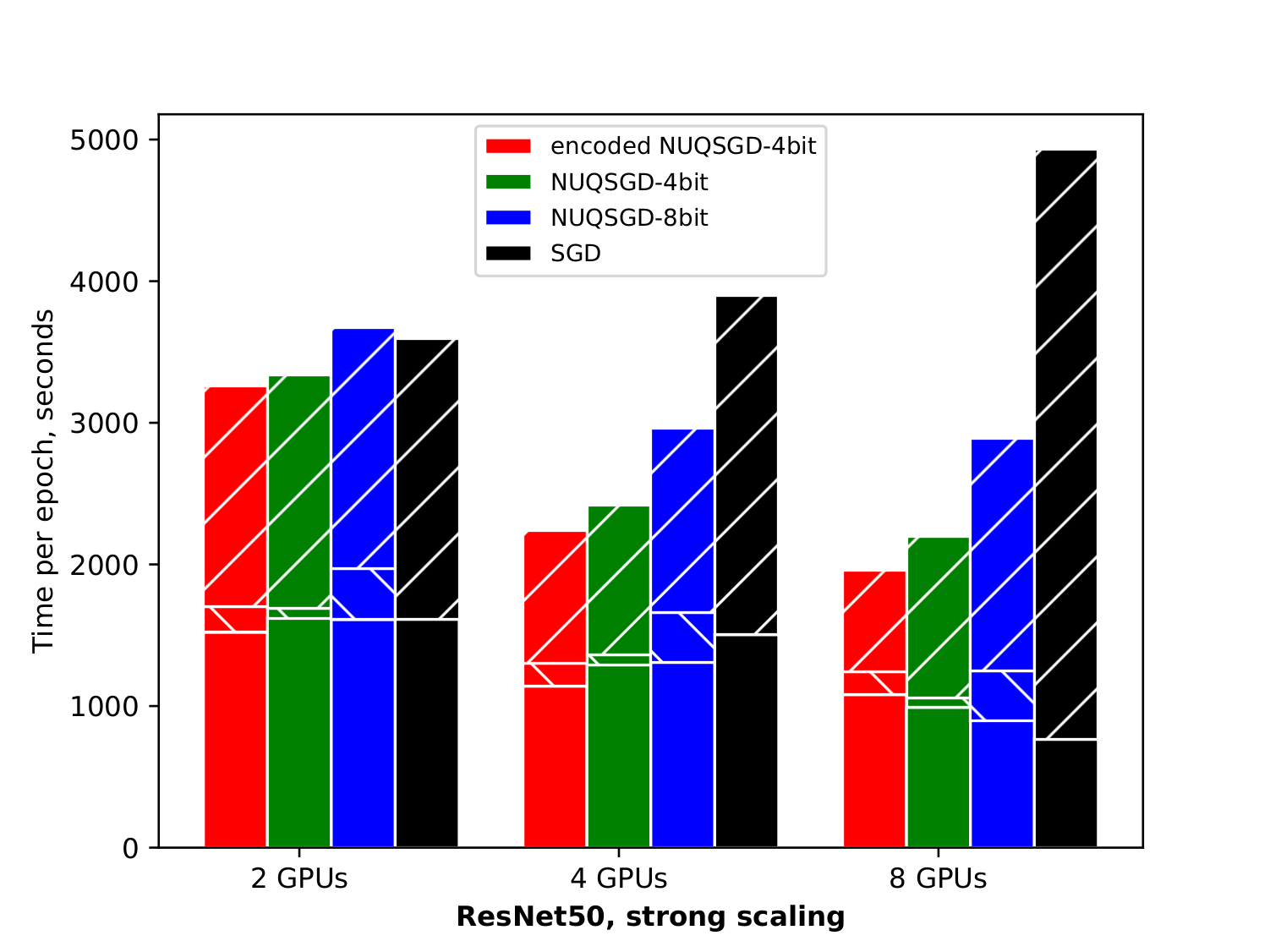 In training deep models over multiple GPUs, the communication time required to share huge stochastic gradients is the main performance bottleneck. We closed the gap between theory and practice of unbiased gradient compression. NUQSGD is currently the method offering the highest communication-compression while still converging under regular (uncompressed) hyperparameter values.
In training deep models over multiple GPUs, the communication time required to share huge stochastic gradients is the main performance bottleneck. We closed the gap between theory and practice of unbiased gradient compression. NUQSGD is currently the method offering the highest communication-compression while still converging under regular (uncompressed) hyperparameter values.
Ali Ramezani-Kebrya, Fartash Faghri, Ilya Markov, Vitalii Aksenov, Dan Alistarh, and Daniel M. Roy, NUQSGD: Provably Communication-Efficient Data-Parallel SGD via Nonuniform Quantization, Journal of Machine Learning Research, vol. 22, pp. 1-43, Apr. 2021.
pdf bib code arXiv
 Communication-efficient variants of SGD are often heuristic and fixed over the course of training. In Adaptive Gradient Quantization for Data-Parallel SGD, we empirically observe that the statistics of gradients of deep models change during the training and introduce two adaptive quantization schemes. We improve the validation accuracy by almost 2% on CIFAR-10 and 1% on ImageNet in challenging low-cost communication setups.
Communication-efficient variants of SGD are often heuristic and fixed over the course of training. In Adaptive Gradient Quantization for Data-Parallel SGD, we empirically observe that the statistics of gradients of deep models change during the training and introduce two adaptive quantization schemes. We improve the validation accuracy by almost 2% on CIFAR-10 and 1% on ImageNet in challenging low-cost communication setups.
Fartash Faghri*, Iman Tabrizian*, Ilya Markov, Dan Alistarh, Daniel M. Roy, and Ali Ramezani-Kebrya, Adaptive Gradient Quantization for Data-Parallel SGD, NeurIPS 2020.
pdf bib code arXiv

My Stellar Team
Christina Runkel, PostDoc Fellow, MLReal Project, INTEGREAT, TRUST.
- Tobias Müller, Ph.D. in progress, UiO.
- Adrian Duric, Ph.D. in progress, UiO.
- Sigurd Holmsen, Ph.D. in progress, UiO.
- Daniel Kaiser, Ph.D. in progress, UiT.
- Johan Mylius Kroken, Ph.D. in progress, UiT.
Zhiyuan Wu, Ph.D. in progress, UiO.
- Esther Zijerveld, MS in progress, UiO.
- Inger Kavlie, MS in progress, UiO.
- Noor Fatima, MS in progress, UiO.
- Arangan Subramaniam, MS, in progress, UiO.
- Frida Marie Engøy Westby, MS in progress, UiO.
- Preben Nicholai Castberg, MS UiO, first job after graduation: full-time at Capgemini.
Kjetil Karstensen Indrehus, MS UiO, first job after graduation: full-time at Bekk Consulting.
- Helene Brodin, summer intern, UiO
- Bror Johannes Tidemand Ruud, summer intern, UiO
- Ola Karlstad, summer intern, UiO
- Josep Peiró Ramos, summer intern, UiO
- Zhenwei Liu, summer intern, UiO
- Røskva Bjørgfinsdóttir, summer intern, UiO.
- Brage Eilertsen, summer intern, UiO.
- Oskar Høgberg Simensen, summer intern, UiO.
- Guri Marie Svenberg, summer intern, UiO.
Karen Stølan Nielsen, summer intern, UiO.
- Co-supervision at the University of Toronto and EPFL
- Anh Duc Nguyen, undergraduate intern, EPFL.
- Thomas Michaelsen Pethick, Ph.D. in progress, EPFL.
- Wanyun Xie, MSc KTH, first job after graduation: Ph.D. at EPFL.
- Fartash Faghri, Ph.D. UoT, first job after graduation: research scientist at Apple.
- Iman Tabrizian, M.A.Sc. UoT, first job after graduation: full-time engineer at NVIDIA.